
如何构建高效的语音识别系统:从基础到使用详解
如何构建高效的语音识别系统:从基础到使用详解
随着人工智能技术的迅猛发展,语音识别系统在各个领域中的使用愈发广泛。无论是在智能家居、虚拟助手还是医疗行业,语音识别技术都在改变人们与机器的交互方式。本文将详细阐述如何构建一个高效的语音识别系统,涵盖基础知识、技术选型、信息应对、模型训练等方面。
一、语音识别基础知识
语音识别(Speech Recognition)是将人类的语音信号转换为可识别的文字信息的技术。语音信号首先考虑的是需要经过采样、特征提取等步骤,最终影响是通过模型进行解码。识别准确率、响应速度和适用环境都是评估语音识别系统性能的关键指标。
二、技术选型
在构建语音识别系统之前,需要选择合适的技术路线。目前主要有两种方法:基于传统算法的声学模型(如隐马尔可夫模型 HMM)和基于深度学习的神经网络模型(如卷积神经网络 CNN、循环神经网络 RNN)。
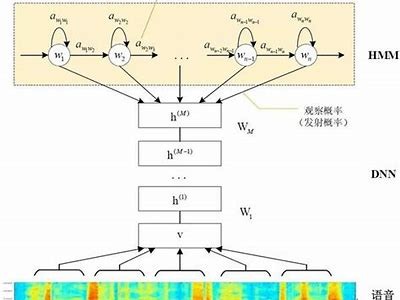
深度学习方法由于其强大的特征学习能力,近年来成为语音识别领域的主流。模型例如长短时记忆网络(LSTM)和Transformer在性能上均优于传统的声学模型。同时,还需要考虑硬件环境,例如CPU和GPU的性能,这将直接影响模型的训练和运行时间。
三、信息应对
构建高效的语音识别系统离不开丰富的信息集。信息的质量和多样性对模型的最终影响是结果至关关键。收集语音信息时,需要确保覆盖多种口音、性别、语速和环境噪声等动因。常用的信息集有LibriSpeech、Common Voice和TIMIT等。
信息收集后,需要经过清洗与标注。语音信息清洗的目的是去除杂音和无用信息,确保训练集和验证集的有效性。标注工作则需准确记录每段音频所对应的文本信息,这为深度学习模型的训练提供了必要的监督信号。
四、特征提取
在语音识别中,特征提取至关关键。常用的特征提取方法包括Mel频率倒谱系数(MFCC)、梅尔频谱和音调特征等。这些特征可以有效提取语音信号中的关键信息,帮助模型更好地区分不同的语音内容。
MFCC是最常用的特征提取技术之一,主要通过对语音信号进行短时傅里叶变换(STFT)得到的频谱图进行应对,提取出对人耳感知最敏感的特征。使用合适的特征提取方法,可以突出提升语音识别系统的性能。
五、模型训练
模型训练是语音识别系统构建的核心环节。首先考虑的是,需选择合适的模型架构并设定超参数。随后,利用准备好的训练信息对模型进行训练。训练过程中需要采用适当的优化算法,例如Adam或SGD,以加速收敛。
同时,训练模型时应注意防止过拟合的困难。可通过加入正则化项、采用信息增强技术和交叉验证等方式来提高模型的鲁棒性。多轮的训练与评估,将帮助您逐步改进模型的性能。
六、模型评估与改进
模型训练完成后,需对其进行评估。评估通常通过计算识别准确率、词错误率(WER)和召回率等指标来判断模型的性能。在此之时,可以对模型的每个组件进行单独研究,以识别潜在的困难。
根据评估影响,可以通过调节超参数、修改模型结构和提升信息集等方式来不断改进模型性能。同时,还可以引入迁移学习的方法,利用在其他领域或任务中训练好的模型,为新任务进行微调,提高识别结果。
七、使用部署
一旦模型达到满意的性能,接下来的步骤是将其部署到实际使用中。这包括选择合适的开发框架(如TensorFlow或PyTorch),创建API接口,整合到明确的使用场景中。为确保模型在实际使用中的流畅性,需对其进行进一步的性能优化。
在部署过程中,还要考虑用户体验,提供简洁易用的交互界面。在此之时,监控模型在实际运行中的表现,以便适时进行调整和优化,确保识别系统的高可用性。
总结
构建一个高效的语音识别系统是一个复杂而系统的过程。通过合理的技术选型、充分的信息准备、科学的特征提取和严谨的模型训练,能够有效提升语音识别的准确率和效率。随着技术的进步,未来的语音识别系统将愈加智能化,使用场景也将进一步拓展。
- 语音识别
- 深度学习
- 信息应对
- 特征提取
- 模型训练
- 使用部署
 上一篇
上一篇
文章评论